The page is organized into three summary cards at the top and a detailed issue list below.
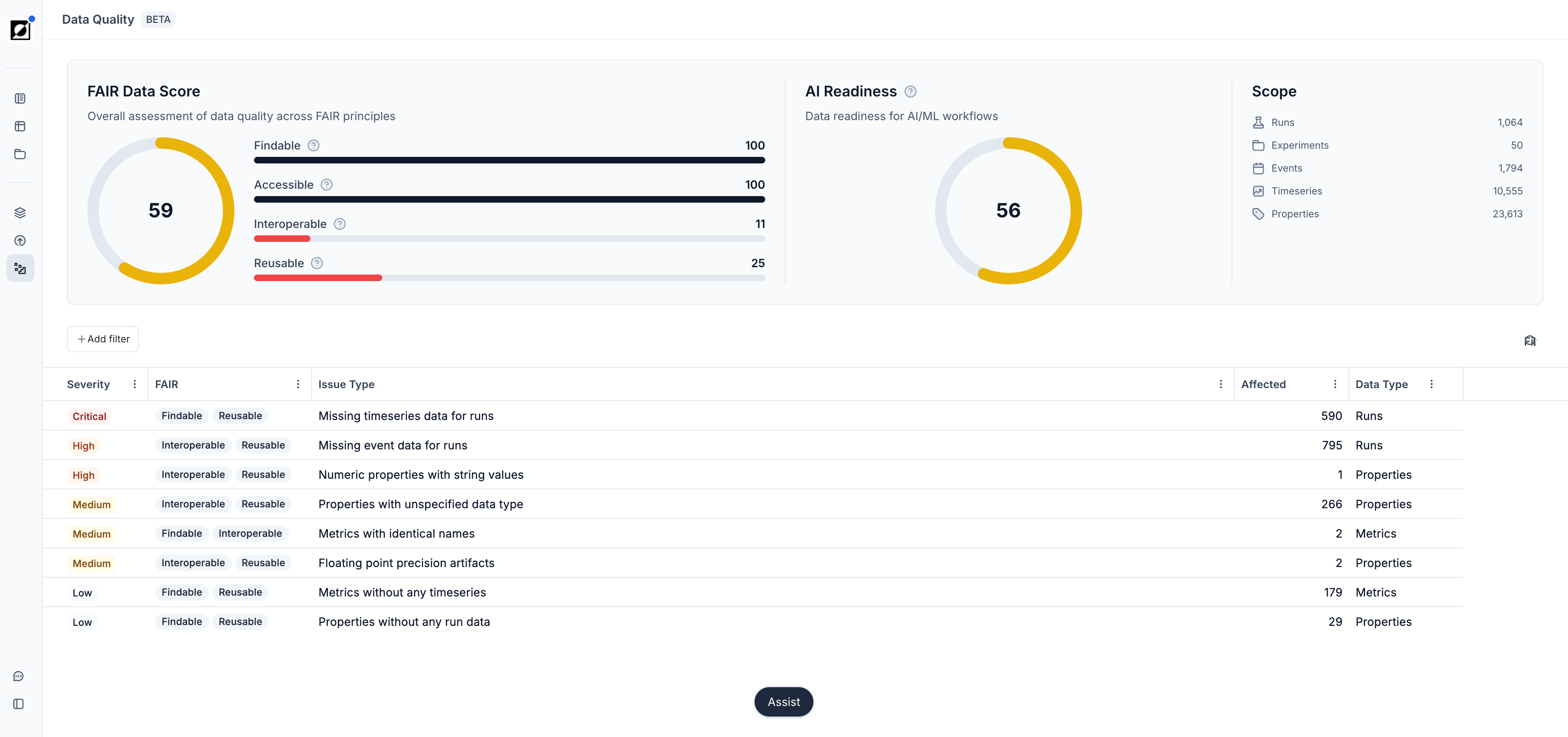
FAIR Score
The FAIR Score measures how well your data conforms to the FAIR data principles — Findable, Accessible, Interoperable, and Reusable. Each pillar has its own score, and the overall FAIR score is displayed as a circular gauge. Hover over each pillar for a tooltip explaining what it measures and how to improve it. Common factors that affect your FAIR score include whether runs are organized into experiments, whether event annotations are present, and whether metrics are grouped under parent metrics with standard names.
AI Readiness
The AI Readiness card measures how well your data is structured for use with Invert Assist and other AI/ML workflows. It tracks three key signals: whether parent metric names are distinctive (not duplicated or overly generic), whether property values are distinctive across runs (sufficient variation for meaningful comparison), and whether metrics are actively used in reports. A higher AI Readiness score means Assist is more likely to produce accurate, specific analyses against your data.
Data Volume
The Data Volume card gives a snapshot of the total amount of data in your workspace — runs, timeseries metrics, properties, and events — giving you a sense of the overall scale of your dataset.
Data Issues
The Data Issues list surfaces specific, actionable problems found in your data. Each issue includes a title, description, severity (Critical, High, Medium, or Low), the number of affected entities, and a recommended resolution path. Issues are tagged with FAIR pillars and AI readiness categories so you can understand their broader impact.
Issues are organized by priority. Click any issue to open a detail panel with a full explanation of why it matters, the recommended resolution steps, and — where possible — a direct link to the affected data in Invert so you can fix it immediately.
Common issue types include duplicate or similar metric names, properties with malformed numeric values, runs not assigned to experiments, and metrics missing from any reports. Many issues can be resolved without leaving the page using the built-in action panels.